8. Examples¶
8.1. Jobs¶
8.1.1. LAMMPS on a single node¶
Here we run one of the LAMMPS benchmark problems using Intel’s Singularity image. In this case we run an MPI job on a single node.
prominence create --cpus 4 \
--memory 4 \
--nodes 1 \
--intelmpi \
--artifact https://lammps.sandia.gov/inputs/in.lj.txt \
--runtime singularity \
shub://intel/HPC-containers-from-Intel:lammps \
"/lammps/lmp_intel_cpu_intelmpi -in in.lj.txt"
This also illustrates using --artifact to download a file from a URL before executing the job. Note that it is not necessary to use mpirun to run the application as this is taken care of automatically.
8.2. Workflows¶
8.2.1. 1D parameter sweep¶
Here we run a one-dimensional parameter sweep. Jobs are created where the variable frame is varied from 1 through to 4.
{
"name": "ps-workflow",
"jobs": [
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "echo $frame"
}
],
"name": "render"
}
],
"factory": {
"type": "parametricSweep",
"parameters":[
{
"name": "frame",
"start": 1,
"end": 4,
"step": 1
}
]
}
}
8.2.2. Multiple steps¶
Here we consider a simple workflow consisting of multiple sequential steps, e.g.

In this example job_A will run first, followed by job_B, finally followed by job_C. A basic JSON description is shown below:
{
"name": "multi-step-workflow",
"jobs": [
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_B"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_C"
}
],
"dependencies": {
"job_A": ["job_B"],
"job_B": ["job_C"]
}
}
8.2.3. Scatter-gather¶
He we consider the common type of workflow where a number of jobs can run in parallel. Once these jobs have completed another job will run. Typically this final step will take output generated from all the previous jobs. For example:
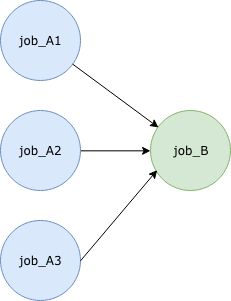
A basic JSON description is shown below:
{
"name": "scatter-gather-workflow",
"jobs": [
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A1"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A2"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A3"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_B"
}
],
"dependencies": {
"job_A1": ["job_B"],
"job_A2": ["job_B"],
"job_A3": ["job_B"]
}
}
8.3. Jupyter notebooks¶
Since all interaction with PROMINENCE is via a REST API it is straightforward to use PROMINENCE from any Jupyter notebook. This can be done directly using the REST API, but here we make use of the PROMINENCE CLI.
Firstly install the PROMINENCE CLI:
!pip install prominence
Import the required module:
from prominence import ProminenceClient
Instantiate the PROMINENCE Client class, and obtain a token:
client = ProminenceClient()
client.authenticate_user()
As usual, you will be asked to visit a web page in your browser to authenticate. Note that the token retrieved is stored in memory and is not written to disk. If the token expires you will need to re-run authenticate_user().
Construct the JSON job description. In this example we use OSPRay to render an image:
# Required resources
resources = {
'cpus': 16,
'memory': 16,
'disk': 10,
'nodes': 1
}
# Define a task
task = {
'image': 'alahiff/ospray',
'runtime': 'singularity',
'cmd': '/opt/ospray-1.7.1.x86_64.linux/bin/ospBenchmark --file NASA-B-field-sun.osx --renderer scivis -hd --filmic -sg:spp=8 -i NASA'
}
# Output files
output_files = ['NASA.ppm']
# Input files (artifacts)
artifact = {'url':'http://www.sdvis.org/ospray/download/demos/NASA-B-field-sun/NASA-B-field-sun.osx'}
# Create a job
job = {
'name': 'NASAstreamlines',
'resources': resources,
'outputFiles': output_files,
'artifacts': [artifact],
'tasks': [task]
}
Now submit the job:
id = client.create_job(job)
print('Job submitted with id', id)
Jobs can be listed and the status of jobs checked. Here are some examples:
# Check status of a particular job
job = client.describe_job(387)
print('Job status is', job['status'])
# List currently active jobs
print(client.list_jobs())
# List last completed job
print(client.list_jobs(completed=True))
# List the last 4 completed jobs
print(client.list_jobs(completed=True, num=4))
# List all jobs with label app=hello
print(client.list_jobs(all=True, constraint='app=hello'))